


千亿规模的 AI 数据赛道进入 Crypto 击球区,DIN 让人人都可以参与数据处理并获得收益 #99
越来越多的用户会关注自己的数据主权和权益,DIN 围绕着「数据」寻找机会,最终把 C 端场景和 B 端需求连接了起来

欢迎上周新加入我们 web3brand 的 102 位朋友!如果你还没有订阅,请在下方输入你的邮箱,和 6,000+ 位聪明好奇的人一起,每周免费获取我们对于 Web3 和 AI 应用的最新案例和深度解析,帮助你做全球化时代的超级个体!
如果你有任何建议、反馈或者合作的想法,欢迎联系我们 [email protected], 每封邮件我们都会及时回复。
本期深度内容由「让人人都可以参与数据处理并获得收益」的 DIN (Data Intelligence Network, 数据智能网络) 为你呈现,enjoy!
欢迎来 Twitter 互动:https://x.com/starzqeth/status/1858308701020717367
为什么在AI的发展正在转向“以数据为中心”?
为什么AI数据赛道是 Crypto 擅长的击球区?
DIN 是如何让人人帮助 AI 模型预处理数据,并获得相应的收益和回报的?还有哪些机遇与挑战?
如果你对以上话题感兴趣,欢迎阅读本文,Enjoy!
1. AI 发展趋势: “以模型为中心”→“以数据为中心”
我在上篇文章《Crypto x AI Agents: 互联网新范式的最后一块拼图》分享过,由 OpenAI 主推的 AI Agent 即将带来互联网新范式,创造数十万亿美金的新市场,而 Crypto 承担了「最后一块拼图」的重任,帮助 AI Agent 轻松的注册ID、拥有财务身份(链上钱包),使得 AI Agent 可以成为真正的「独立个体」,自主执行任务,释放出最大潜力。
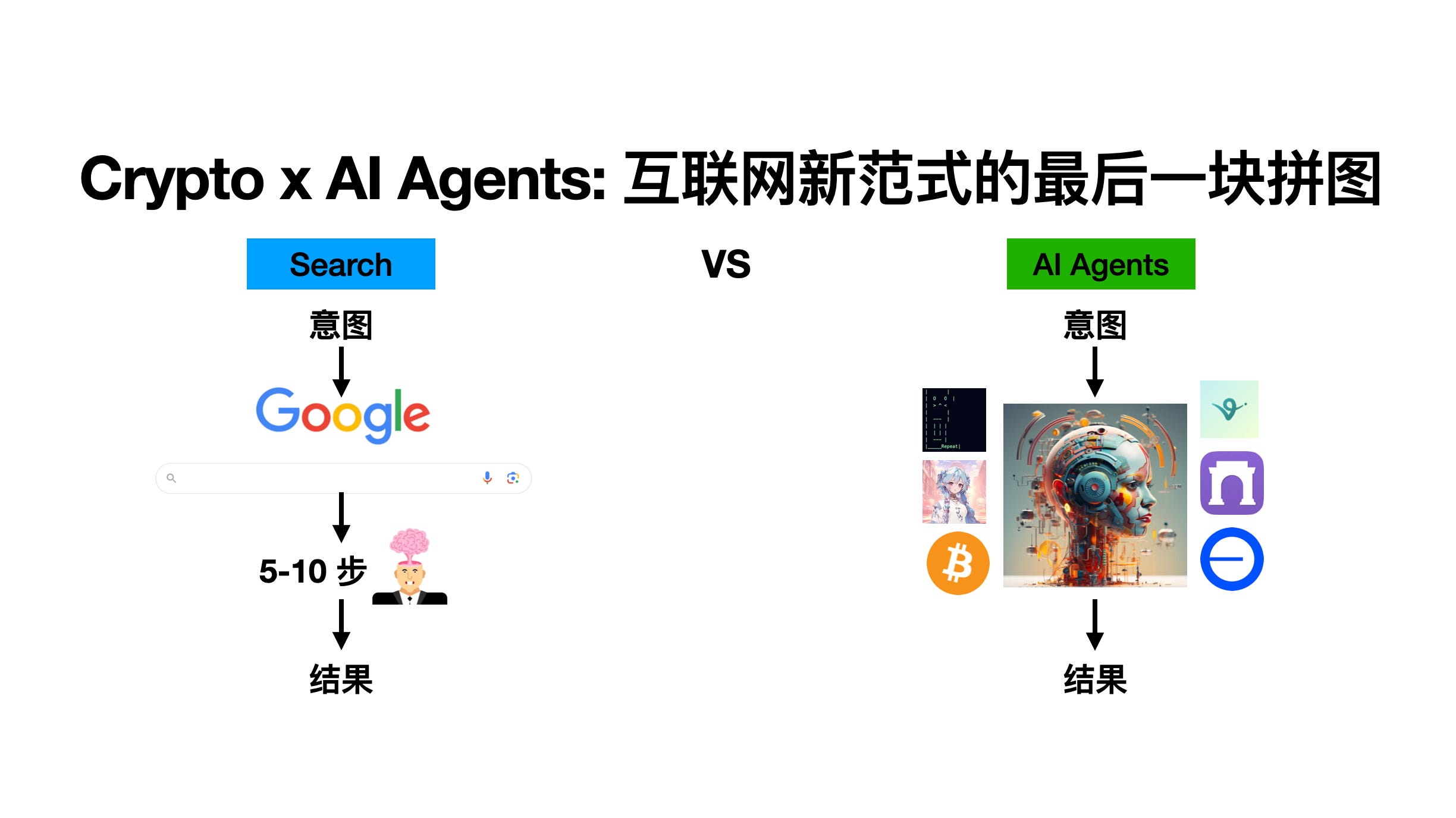
要训练出色的 AI Agents, 必然少不了算力、算法、数据三件套。在这其中,我认为「数据赛道」还蕴含着不少的机会,特别是在 1-3 年的时间尺度里。
Why 数据?
因为这个行业一开始大概率是由中心化头部公司来引领的。而对于微软/谷歌/OpenAI 这种体量的公司,算力可以采购英伟达,算法可以高薪聘请研究员和工程师,但数据呢?需要找第三方采购。
Reddit: 今年年初和谷歌签署了一份每年 6000 万美元的数据授权协议,允许谷歌使用其内容来训练 AI 模型;Reddit 也和 OpenAI 等公司签署了类似的数据授权协议,总收入达到了 2.03 亿美元;
Twitter: 2023 年 2 月,Twitter 宣布将不再提供免费读取推文数据的 API, 一方面是马斯克希望用 API 增加收入,另一方面也不希望其他 AI 公司免费爬数据来训练模型。最基础的档位一个月 $100 但只能获得 1 万条推文数据;专业版一个月 $5000 可以获得 1 百万条推文数据。对于训练模型来说,一个月 1 百万条肯定是远远不够的,再要增加的话就需要使用企业版了,最低一个月 $42,000.
为什么像 Reddit 和 Twitter 这样的公司敢于给自家数据卖出高价呢?因为模型不断往前发展,算力是体力,算法是脑力,数据是知识,三者缺一不可。
在计算机科学中,有一句俗语“Garbage in, garbage out”(垃圾进,垃圾出);对 AI 模型也是如此,只有高质量的数据输入,才会产出优质的 AI 模型。
, a Concept in Computer Science Stock Vector - Illustration of statistic, stats: 289268999")
同时,历史数据即将被 AI 模型们耗尽,所以能源源不断产出高质量增量数据的平台需求暴涨,凸显价值,特别是可以产出自然语言语料的 Reddit, Twitter 这类社交网站。
GPT-4有着超1.8万亿参数和13万亿token的训练数据,相当于自1962年开始收集书籍的牛津大学博德利图书馆存储的单词数量的12.5倍;谷歌的 Gemini 是在英语维基百科和 BookCorpus 中包含33亿单词的数据集上进行训练的,微软的 Turing-NLG 是在英语网页中超过170亿个词组的数据集上进行训练的;
研究机构Epoch报告,在未来两年内,AI训练将用尽互联网上包含音视频在内的高质量数据格式。
(以上 Source: OpenAI,困于数据短缺)
这个行业的大佬们也意识到了这一点:
Sam Altman去年就表示,单纯增加大型机器学习模型的参数数量,并不是提高模型性能的最佳途径,获取和利用大规模的、高质量的数据,以及对数据进行高效的工程化处理,才是提升模型能力的关键因素。
知名AI学者吴恩达也曾表示,AI发展正在从“以模型为中心”加速转向“以数据为中心”。
2. 千亿规模的数据赛道,进入 Crypto x AI 击球区
那么「数据赛道」有多大呢?
上面已经提到,光是 Twitter 和 Reddit, 每年卖给大公司的数据就价值数亿美金。
同时,有一家隐性小巨头 ScaleAI,也正在从数据赛道里面受益:年收入近 10 亿美金,估值 138 亿美元。
一家公司估值就达到 138 亿美元,说明这个赛道至少是千亿美金的规模。
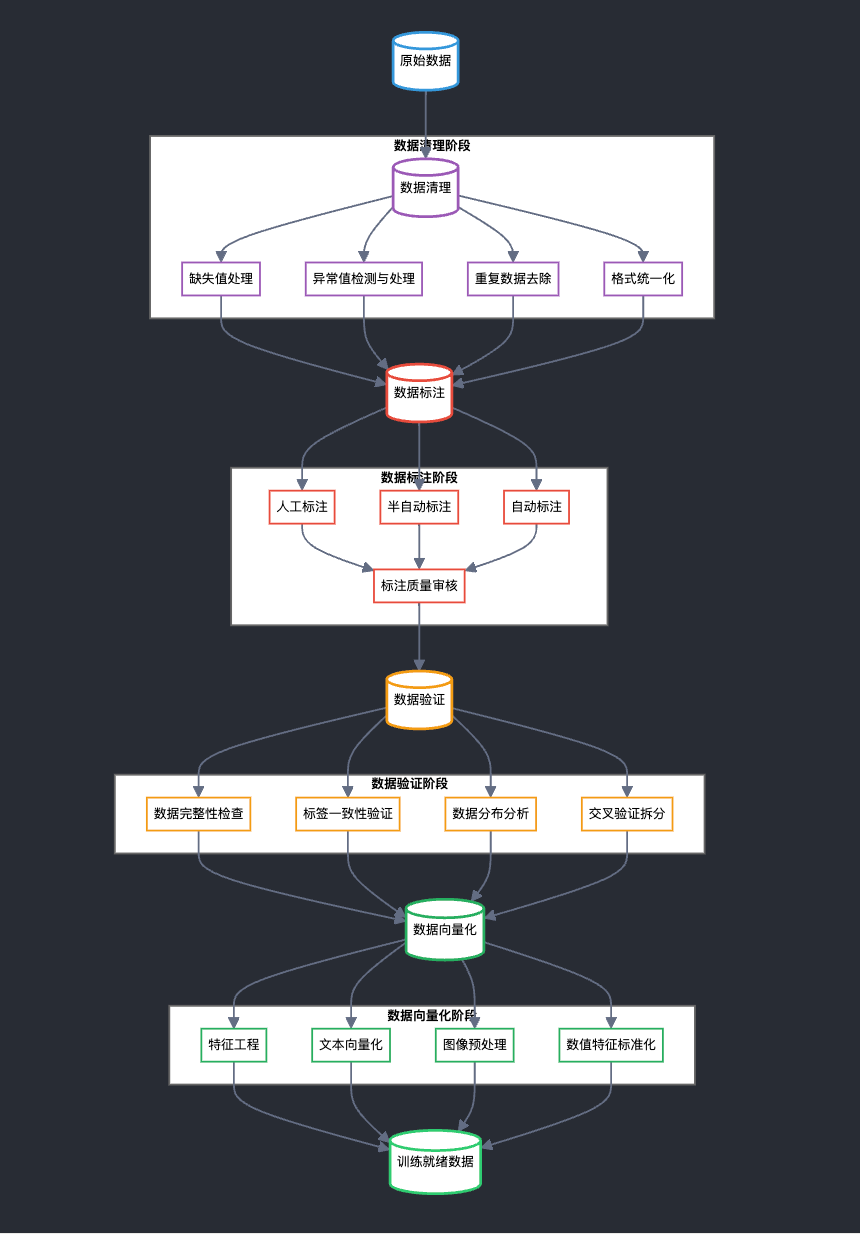
这里面有个冷知识,网上的语料是没法直接给 AI 模型使用的,需要一系列预处理,特别是「数据标注」
如果说英伟达是算力的卖铲人,数据标注公司是数据的卖铲人。
早期,为了让AI更好地认识世界,需要人工标注数据投喂给机器学习。到了现在,虽然自动化数据标注取代了人工,但仍然需要非常专业的人士来写词条,针对相应的问题和指令,给出符合人类逻辑与表达的高质量的答案。
但这活又苦又累,大公司不愿意花精力做,自然也给了创业公司更多的机会。Scale AI 就是这样一步步脱颖而出。2023年,Scale AI公司的年化收入高达 7.5 亿美元,其客户几乎涵盖了美国 AI 各细分赛道的皇冠上的明珠。
Reference: 数据标注做到了138 亿美元估值,Scale AI凭什么?
ScaleAI 业务运营的起家方法是典型的「地理套利」,一个典型的例子,OpenAI给合作方的时薪是12.5美元,经过层层外包,ScaleAI 最后给肯尼亚外包的时薪不到 2 美元(目前 ScaleAI 也增加了一定比例的 AI 标注)。
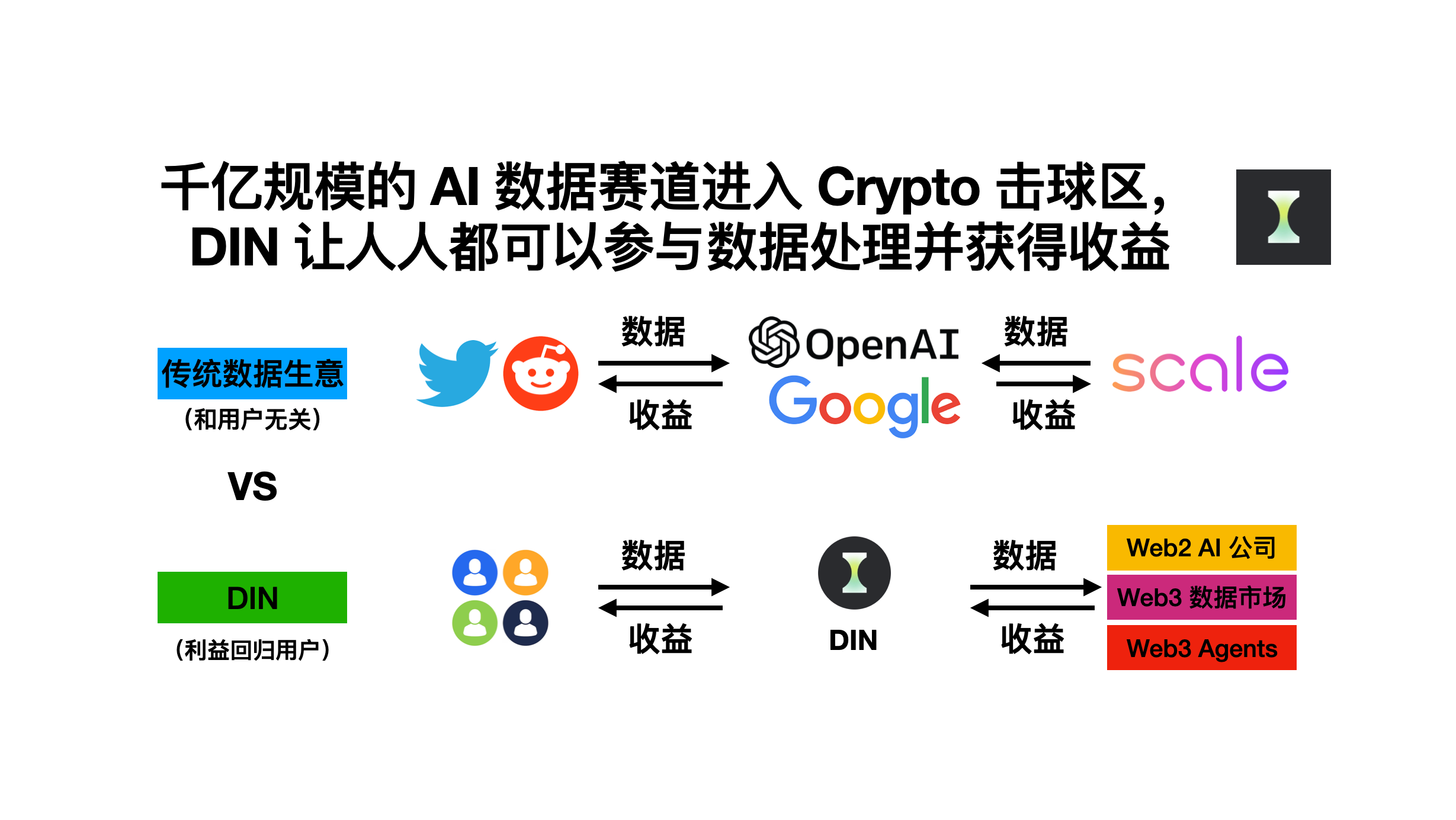
以上特点,让这个价值千亿的 AI 数据赛道也落入了 Crypto 擅长的击球区:
Twitter 和 Reddit 卖给大公司价值数亿美金的数据,都是用户自己产出的,但用户本身并没有获得任何收益;
ScaleAI 这样的打标平台,建立在一层层的「中间商赚差价」上,一方面降低效率,另一方面也减少了实际工作者的利益。
那有没有这样的平台,可以跳过中间商,让用户自己来参与数据预处理,直接获得对应的奖励呢?
答案是 Yes, 我们今天给大家介绍的 DIN(Data Intelligence Network, 数据智能网络) , 就是在打造这样一个平台,让人人帮助 AI 模型预处理数据,并获得相应的收益和回报。
同时由于跳过了各种中间商,DIN 可以做到比传统的数据供应商更低的成本。实现用户、模型使用方、DIN 三方共赢。
而且每天已经有 70w 用户在上面活跃了,有点意思。
3. DIN: 让人人都可以参与数据处理并获得收益
DIN 是第一个模块化AI数据预处理层(The Modular AI-Native Data Pre-Processing Layer),官网上的 Slogan 叫做“Cook data for AI and get paid” (为AI“烹饪”数据并获得收益)。

熟悉我的读者都知道,我不太喜欢用「大词」来介绍,我们直接看 DIN 是如何实现「让人人都可以参与数据处理并获得收益」的。
DIN 由 2 个产品构成
xData: 用户通过这个产品进行数据收集与标注;
Chipper Nodes: 节点持有者可以通过运行程序,进行数据验证和向量化,最终生成喂给 AI 的数据。

3.1 xData
xData 是 DIN 上的 AI 数据收集与标注产品,于2024年4月初在 opBNB 上启动。
用户只需要安装 xData 的浏览器插件+连接钱包,在任意一条推文评论区点击“GODIN”按钮然后回复,就可以完成这条推文的收集和标注,并获得相应的积分 Wafer.
然后 Wafer 可以通过后续的节点预挖矿活动转换为链上代币 $xDIN,最后获得主代币 $DIN空投。
目前每个用户一天可以“GODIN” 6 次,获取上百 Wafer 积分。如果每天都玩的话,一个月可以有 3000 左右的 Wafer, 实现了去掉中间商,直接让每个人来参与数据收集和标注,并得到一定的收益(希望可以换几顿猪脚饭哈哈)。
而且这件事对发展中国家的用户非常友好,他们可以把收益在链上直接换成 USDT (还可以通过 staking 生息), 而不是面临通胀的本国货币,实现了某种程度上的美元民主。
同时这个过程也实现了数据上链,把链下数据存储在 BNB Chain 上的去中心化数据层 BNB Green Field 中。这也增加了数据的透明度,方便后续继续将数据的使用和奖励挂钩。
不过这里我觉得还可以有 2 个优化的地方
目前奖励的只是「数据收集者」,其实可以把「数据生产者」也就是推文作者纳入到激励体系里面来,形成对特定内容的激励机制,这样 DIN 的价值不止是数据的处理,还有数据的生产,天花板会更高。
目前的标注流程也相对简单,未来可以增加更多标签,提升数据的质量。
3.2 Chipper Nodes
用户通过 xData 收集和标注的数据,其实还不能直接用来训练 AI 模型,还有 2 个重要的环节:
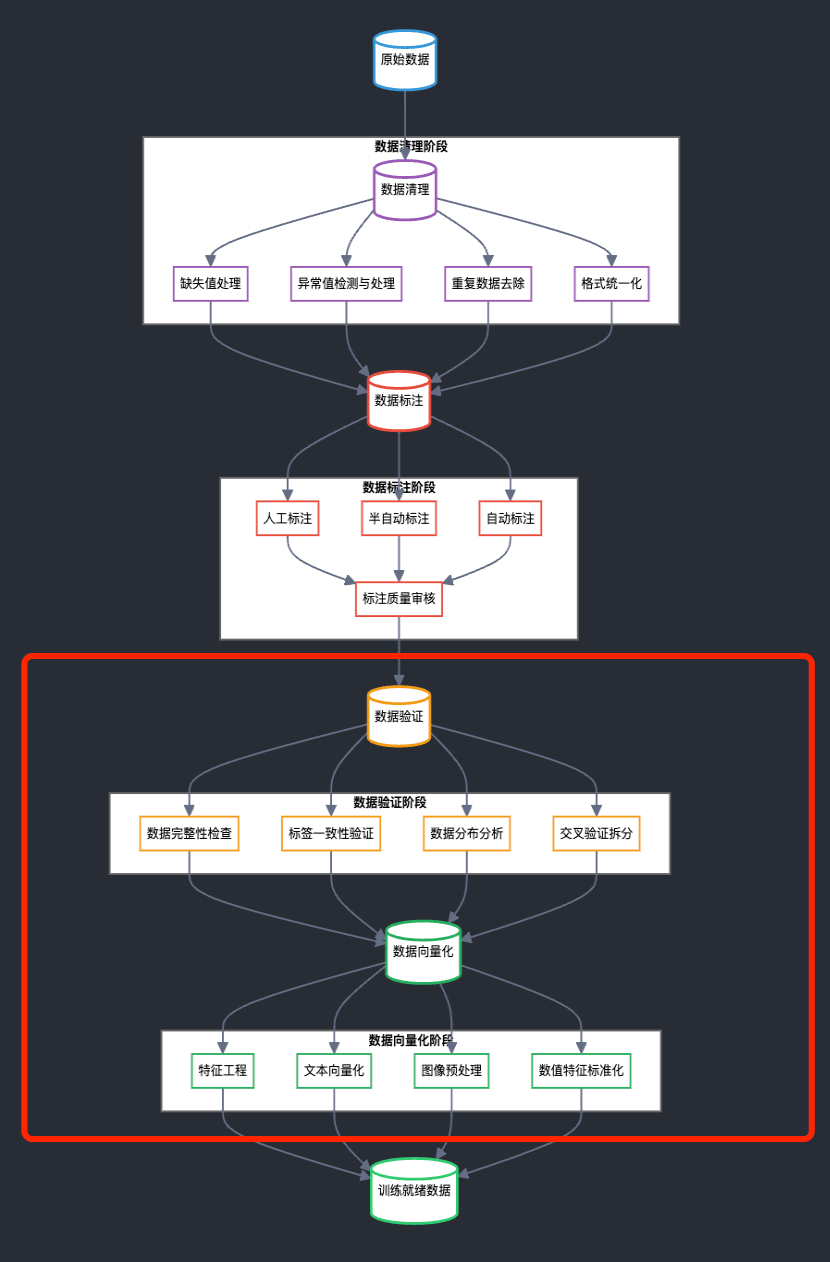
数据验证(Data Validation):保证数据质量和完整性,剔除 Bot 参与;
数据向量化(Data Vectorization):因为 AI模型只能处理数值数据,不能直接处理文本、图像等原始数据,所以需要通过向量化来将各类数据转换为数值形式,使模型能够进行数学运算(下面给出 2 个例子)。
# 文本向量化示例
# 原始文本:
text = "机器学习很有趣"
# 1. One-hot编码(词袋模型)
# [0,0,1,0,...,0]
# 2. Word2Vec嵌入
# [-0.2, 0.5, 0.1, ..., 0.3]
# 3. BERT编码
# [[0.1, -0.2, ...], [...], ...]
# 图像向量化示例
# 原始图像:
image = load_image("cat.jpg")
# 1. 像素值归一化
# [[0.4, 0.5, 0.6],
# [0.3, 0.4, 0.5],
# ...]
# 2. CNN特征提取
# [0.2, -0.1, 0.4, ..., 0.3]可以看出,【数据验证和向量化】相比【数据收集和标注】,需要不少计算量,于是 DIN 推出了第二个产品 Chipper Node, 节点持有者可以下载节点程序在自己的电脑上运行(普通 PC 就可以跑),也可以代理给第三方运行。
用户在跑节点时候,一方面进行 DIN 网络里的数据验证和向量化处理,另一方面可以获得对应的 $xDIN 代币奖励(TGE 时转换为 $DIN, 据说还会在第三方盘前交易市场开放交易)。
通过 Chipper Node, DIN 把「数据验证和向量化处理」的工作也去中心化的分配给用户,让运行节点的用户来享有对应的激励。
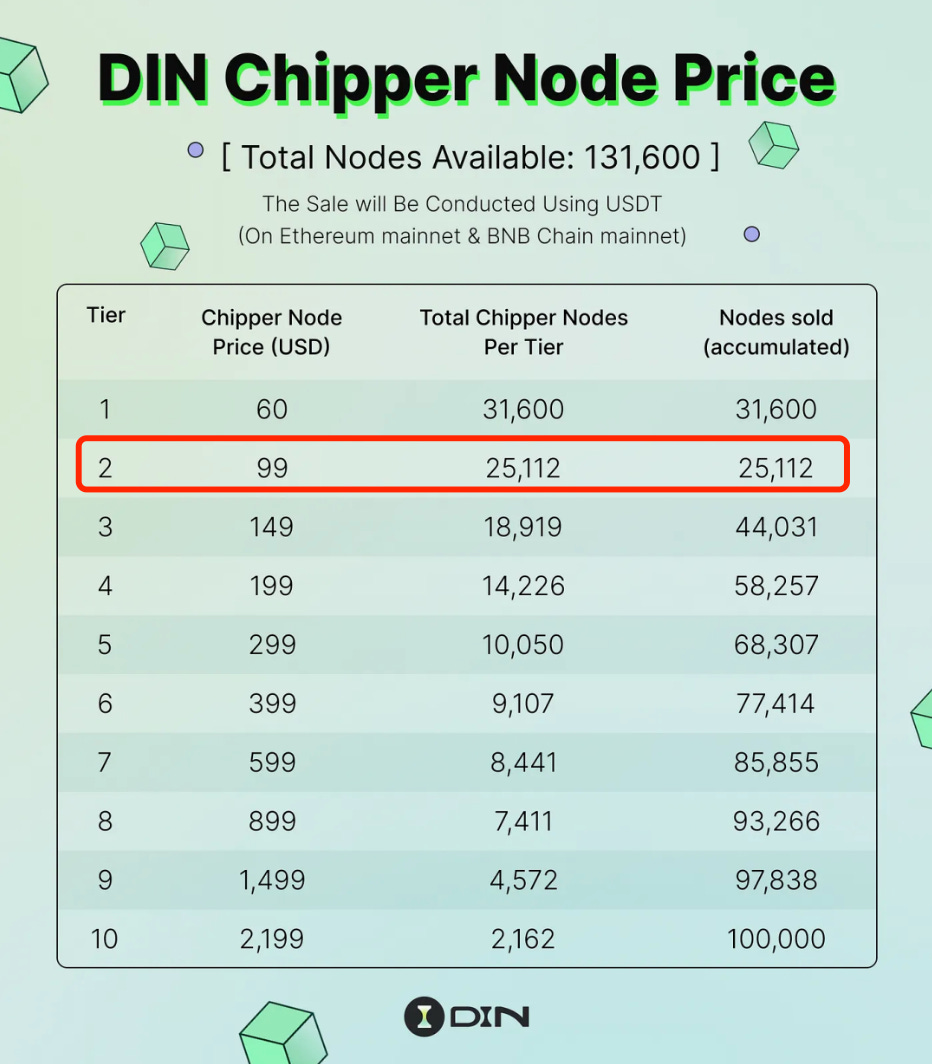
购买节点本身也自带DIN空投(具体见白皮书),还能在TGE之后有单独的矿池,分享DIN总量的 25%。
节点这个模式本身也是用户分层运营的一种,可以筛选出了高质量的贡献者,为项目的发展带来源源不断的推动力。
目前 DIN 有超过3万名节点持有者,第一期节点销售已经在 9月底结束,Tier 2 节点全部售罄,获得总销售额 250万美金。
下一期节点销售也即将开始,感兴趣的朋友可以关注之。
3.3 数据表现
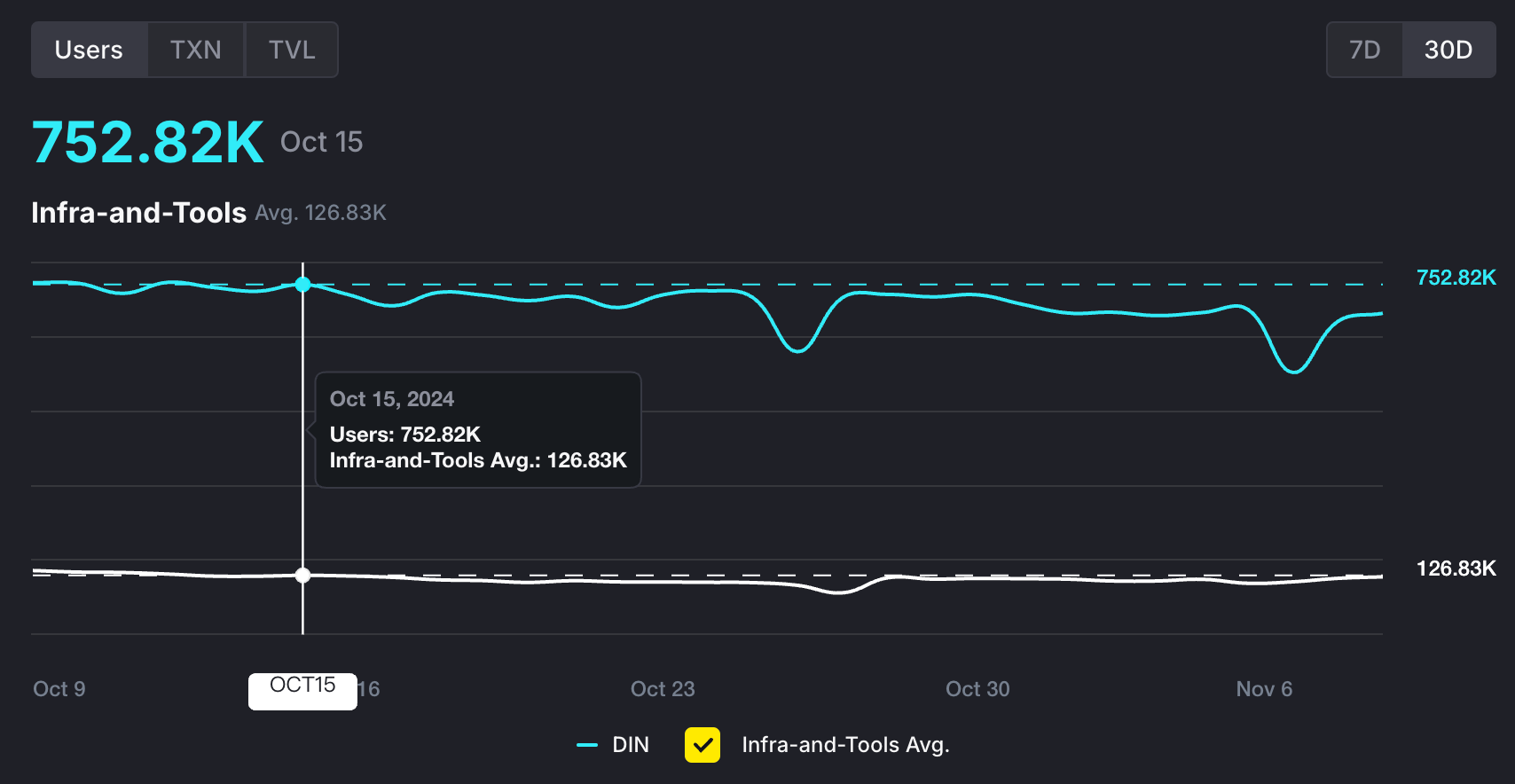
Dappbay 上列出了所有 BNB 生态项目 dApp 的数据,可以看到 DIN 的日活跃用户量近 30 天都在 70w 上下,日交易量则在 120w 上下,都远超”Infra-and-Tools”这个赛道下的平均值。
这里面绝大部分都是使用 xData 来收集数据以获得激励的用户,每 24 小时都需要重新在 opBNB 上交易验证,反应了用户的活跃度和热情。这也得益于 xData 简单易用,只要安装一个浏览器插件 + 连接钱包即可。
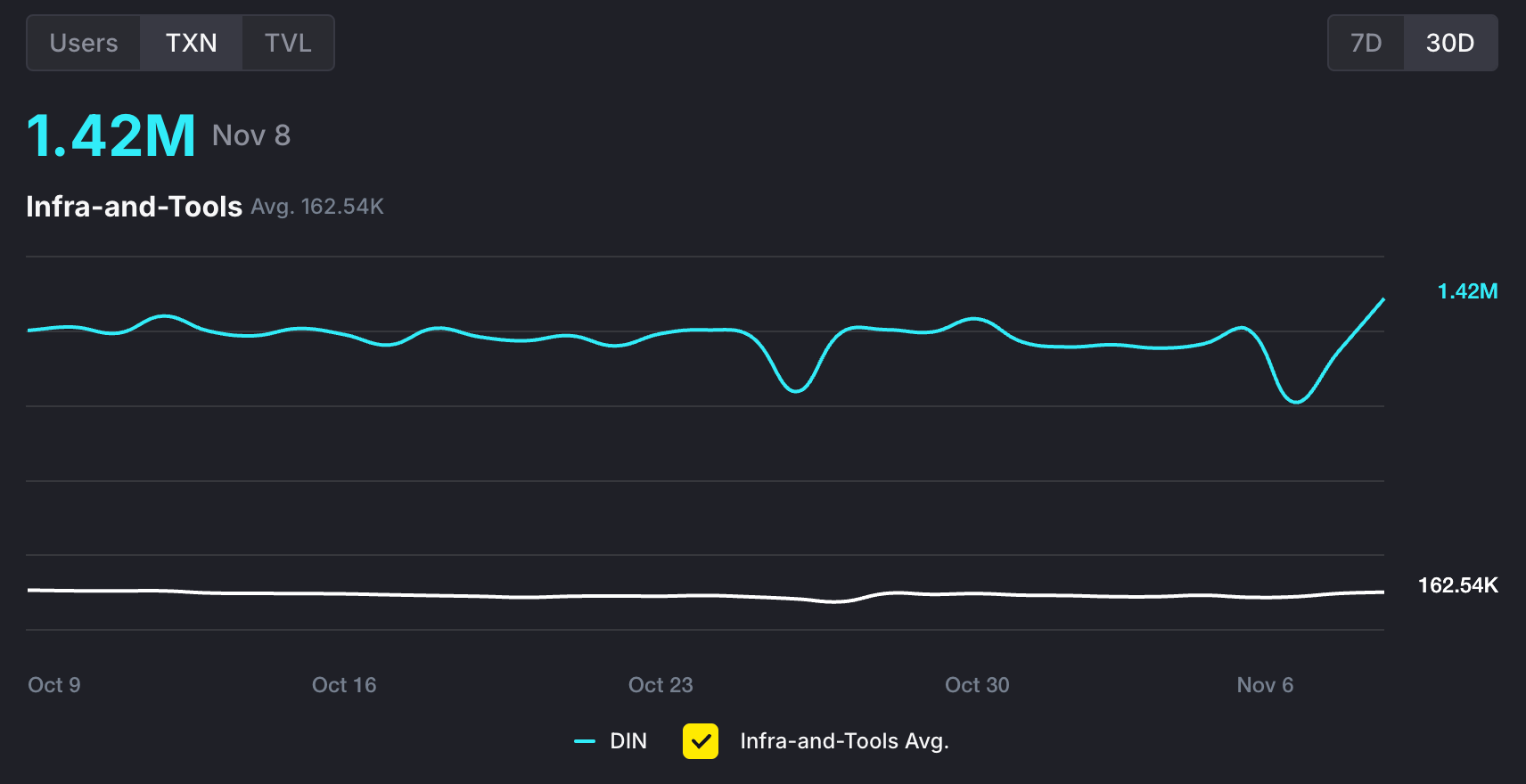
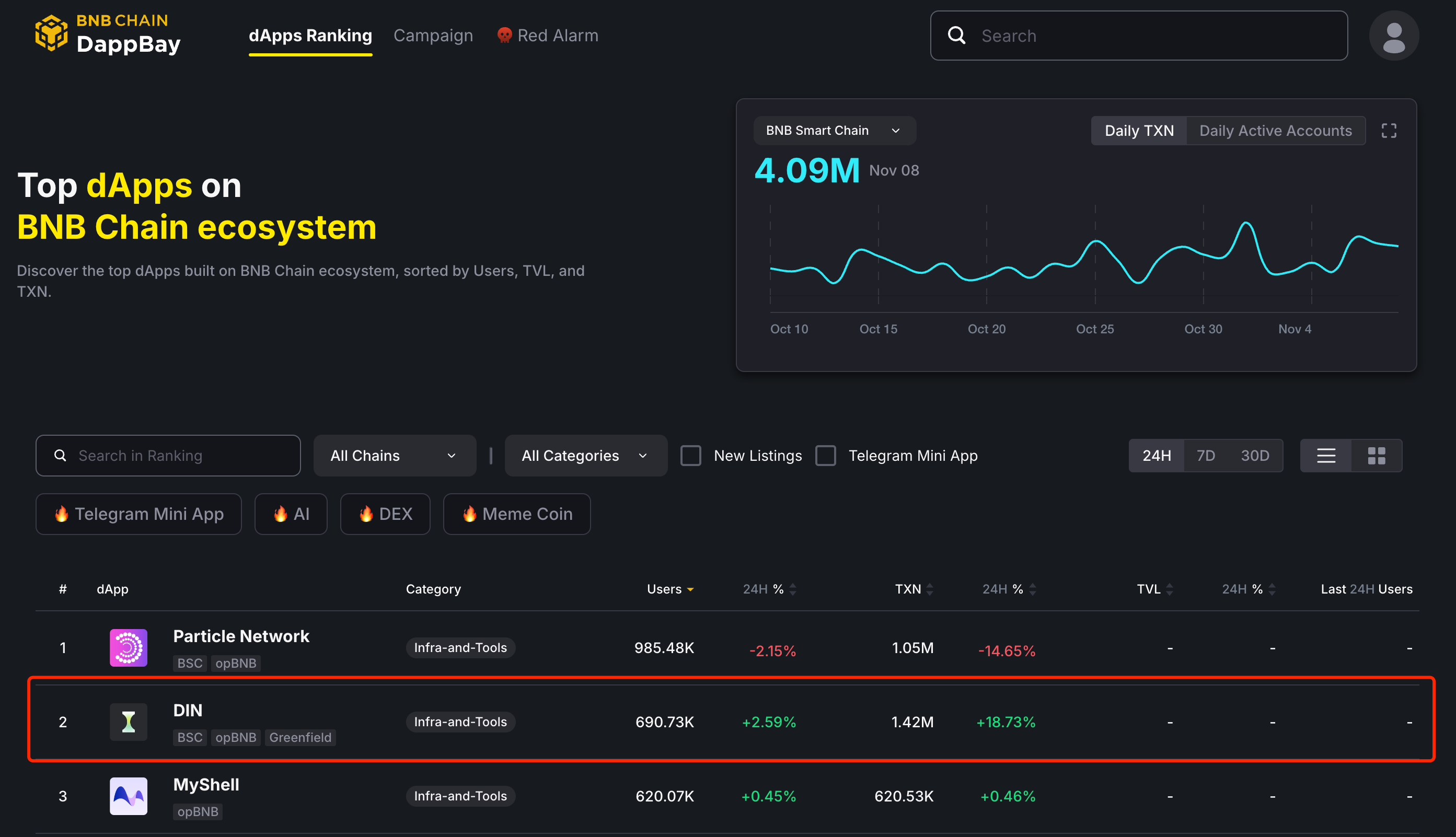
在整体排行榜上,DIN 在 24h / 7D / 30D 都保持在前 10. 有意思的是,在下面这个 24h 的排行榜中,DIN 排第 2 名,第 1 名 Particle Network 和 第 3 名 MyShell 我都写过 ; )
3.4 商业合作
分析完了产品和用户,我们来看看用户贡献的数据都用在了哪里。
DIN 目前的商业合作分 3 类:
数据输出
机器人输出
场景扩展
数据输出
今年 9 月,DIN 与领先的 AI 数据资源及服务提供商“核数聚科技”达成战略合作,为其及合作伙伴提供高质量的AI训练数据。
核数聚科技专注于为 AI 企业提供一站式定制数据解决方案,客户包括思必驰,博世,网易、科大讯飞等科技巨头。
用户在 Web3 收集的数据提供给 Web2 公司用来训练 AI 模型,刚好回应了前面我们讲到的场景
让人人帮助 AI 模型预处理数据,并获得相应的收益和回报。
同时由于跳过了各种中间商,DIN 可以做到比传统的数据供应商更低的成本。
用户、模型使用方、DIN 三方共赢。
如果比传统的数据供应商成本更低,质量更高,模型使用方有什么理由拒绝呢?希望在未来看到更多这样的合作。
机器人输出
除了数据输出之外,DIN 还做了一件有意思的事情。基于用户收集的数据,DIN 自己训练了一个 AI 社区管理机器人服务,集成到 BNB Chain 官方的 Discord 社区中,成为 BNB Chain 官方的的 AI 服务提供商。
DIN 把这套创建聊天机器人的能力也开放给了用户,上线了一个创新产品——名为 Reiki 的机器人创建服务,尝试 AI 时代的创作者经济,还拿过 Product Hunt 当天和当月的第一名。
场景扩展
今年 6 月,DIN 宣布与以太坊 L2 Mantle 达成合作,Mantle Network 的用户也可以使用 xData 来收集数据,赚取Wafer积分,有机会锁定未来的 DIN 代币空投权益。
通过此次合作,DIN 从一开始的 opBNB 开始进行多链部署扩展用户和生态,合作方(比如 Mantle Network)也可以通过 DIN 的设施来建设 AI 生态,形成双赢。
3.5 团队和融资
DIN 这个名字看起来有点新,但其实从 2021 年就开始了项目的建设。当时的名字叫做“Web3Go”,最初的方向是Polkadot(波卡)生态的链上数据分析产品。
2022 年 Web3Go 进入了 BNB 生态,参与了 Binance Labs 举办的MVB第5期孵化器,并最终以“多链开放数据分析平台“的定位拿到 Binance Labs 的领投👏, 同时Haskkey Capital, NGC Ventures 等知名基金跟投,一共 400w 美金。
2023 年 Web3Go 进行了定位升级,从“链上数据服务商”升级为“Data Intelligence Network (数据智能网络)”,开始 Crypto x AI 方向的探索,提供“链上数据看板”和“链下数据训练AI Agent”两方面服务,长期服务Manta Network(都做过波卡生态)、BNB Chain等客户。
2024年项目进行了品牌升级,正式改名为 DIN, 定位为“首个模块化的AI原生数据预处理层”,启动了前面我们介绍的 2 个产品,AI数据收集与标记产品xData和AI数据验证与处理节点Chipper Node.
在今年 8 月,DIN 再次获得 400w 美金融资,投资方包括 Manta Network、Moonbeam、Ankr 和 Maxx Capital, 总融资额达到 800w 美金。
团队核心成员毕业于哥伦比亚大学、伦敦大学学院、斯图加特大学等全球知名高校。CEO Hao在人工智能领域有着数年的经验,同时曾在身份聚合器Litentry担任VP, 帮助其在币安成功上币。
因为我自己也创过业 pivot 过,我最直接的感受是,团队的韧性还挺强的,一直在围绕着「数据」寻找机会,最终把 C 端场景和 B 端需求连接了起来。
而且 800w 美金其实并不多,但 DIN 的整套产品还挺齐全,侧面说明团队的战斗力不错。
4. 机遇与挑战
最后谈一下我的想法
AI Agent 即将给整个 AI 领域带来颠覆性的变化,而数据会成为模型训练的关键,特别是 Agents 需要的拟人化数据和各类业务知识;
千亿规模的数据赛道,进入 Crypto x AI 击球区,同时越来越多的用户会关注自己的数据主权和权益:
自己的数据,被 Reddit / Twitter 拿去卖钱;
发展中国家的标注员,被中间商层层克扣;
但实话说,人人都能看到的赛道,「卷」是必然的
共享爬虫网络 Grass 已经上币,流通市值 7.5 亿美金,FDV 31 亿美金,堪称这个赛道的龙头。逻辑更简单粗暴,用户下载一个Chrome 插件在电脑上跑节点,节点就直接开始爬数据,数据经过清洗和结构化用于训练大型语言模型(LLM),同时建立一个透明的数据市场,为所有参与者提供奖励(参与者其实就是共享自己的电脑来去中心化的爬数据,以跳过 Reddit / Twitter 对爬虫的集中封锁😂)。类似的项目也有不少。

在「卷」之下必须做出差异化。DIN 的更多可能性包括:
DIN 的一个优势是用户在人工采集,其实是承担了 Curator 的角色,这可以是非常有意思的一件事,有机会让采集者打上更多的标签,提升数据质量,高质量的数据永远是最受模型欢迎的;
另外,如果把数据生产者」也就是推文作者纳入到激励体系里面来,形成对特定内容的激励机制,这样 DIN 的价值不止是数据的处理,还有数据的生产,天花板会更高。
有一件事是是所有的数据采集项目都需要关注的,未来跑节点和采集数据的,可能不再是人类,而是 AI Agents. 如何开发面向 AI Agents 的产品,可能会成为核心竞争力。

我会继续对这个赛道和相关的项目保持关注。
FIN
(我们的研究和观点仅代表个人看法,不作为投资建议,DYOR)
5. Reference
我们每周一封邮件,深度解析Web3和AI应用,帮助你做全球化时代的超级个体,创造属于自己的故事,拥有自己的个人品牌
如果你觉得我们的内容对你有帮助,请订阅我们的 Newsletter,并多多推荐给朋友。你的支持是我们创作内容的最大动力。
最后欢迎通过打赏或付费订阅来支持 Web3Brand
打赏地址
捐赠平台:Web3Brand @ Giveth (平台会奖励$GIV)
ETH:0x80749d65a5790e4BED42B6735fc5321Ce8de2319
BTC:bc1qp26ljfpzmu4p3tvgrrmdx7h4cuzz5c9gqv54hr
SOL: CG6eEJFYuEsAEMsdJxomEDkVWMgxRMT5v4u1gKNoVcsb
Doge: DEN9XmHCXvbLQAKrZUZZHZBSyyY1uhpNs4
TON: UQDmT8U8AUVvjOCmfQemABi1auZn6unACxGVDeU9t1cqJ0ee