


GPT-4: 多模态模型即将开启人工智能的新篇章

本周值得关注的big thing: GPT-4 发布
目前的GPT-3.5只能理解文字,所以之前推荐的Youtube摘要工具glarity只能基于有字幕的视频 。
而GPT-4是多模态模型,可以同时理解图像、声音、文本和视频。也就是说,万物皆可作为输入和输出,AI 可以直接通过摄像头和扬声器和人类沟通,越来越像「人」甚至超越「人」。
也许未来某一天, 你很难分辨出来对面的是人还是机器人。改变人类的通用人工智能(AGI)和西部世界要来了吗?
本文带你从月初已发布的多模态Kosmos-1模型略窥一二👇

多模态语言模型Kosmos-1
3月初微软低调推出了一种名为 Kosmos-1 的多模态语言模型 MLLM,输入源从GPT-3.5 的文本扩展到了图像,并提供了论文下载,感觉就是在为GPT-4的发布铺垫
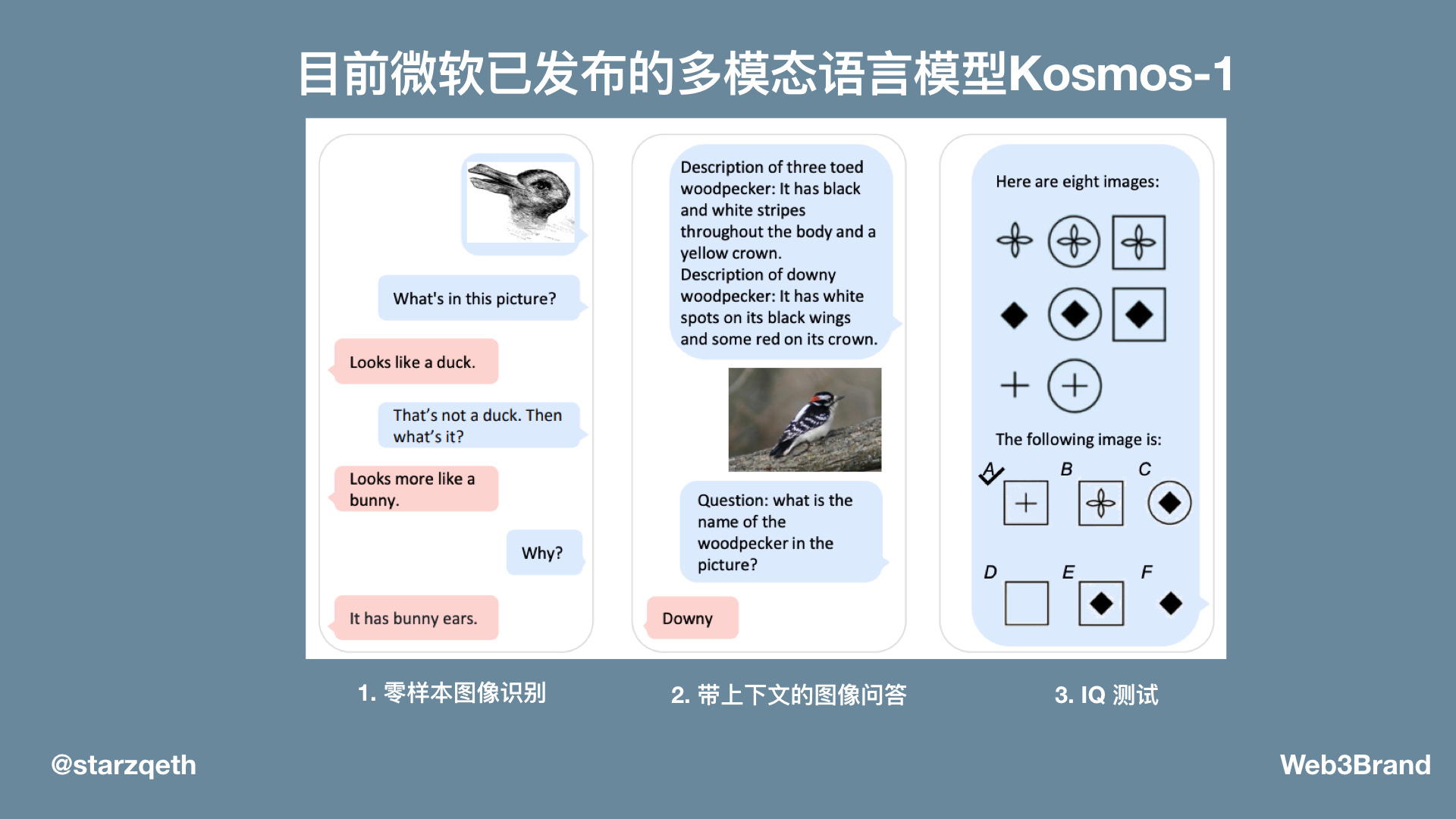
示例1展示了Kosmos-1的3大关键能力
零样本图像识别:识别出兔子
带上下文的图像问答:分辨出绒啄木鸟(downy)
以及图形推理:完成需要理解图形规律的 IQ 测试
我梳理了这篇论文的摘要
能够识别语言和图像,在上下文中学习和生成文本输出
可应用于语言任务(如推理,理解,生成,文字分类)和视觉任务(如图像识别,描述,提问,答复)
该模型基于Transformer语言模型,并使用一个名为Magneto的预训练模型,具有 1.6 亿参数
训练目标是预测下一个token,输入包括文本,图像嵌入,文档
能够在上下文中学习新的概念和关系,例如根据给定的图片或声音识别出其中的物体或动作 5. 该模型在数据集(如 MSCOCO,Raven IQ, Hateful Memes)上进行评估,并与其他模型(如 Clip 和 Flamingo)进行比较
其在语言和视觉任务上获得了不错的结果,且超过其他基准模型
作者还介绍了一个新颖的数据集——Raven IQ test,用于评估 MLLMs 的非语言推理能力
作者认为 MLLMs 是实现人工通用智能(AGI)的关键一步,并展望了未来可能面临的挑战和机遇
Kosmos-1完整能力&示例
完整能力
语言任务
语言理解
语言生成
OCR-free文本分类
跨模式转移
常识推理
非语言推理
智商测试(Ravev渐进矩阵)
感知语言任务
图像说明
视觉问答
网页问答
视觉任务
零样本图像分类(zero-shot classification, ZSC)
带描述的零样本图像分类
示例 2
- 图像解释(1)-(2)
- 图像问题回答(3)-(4)
- 网页问题回答(5)
- 简单数学计算(6)
- 数字识别(7)-(8)

示例 3
- 图像说明 (1)-(2)
- 图像问题回答 (3)-(6)
- OCR (7)-(8)
- 基于图像的对话 (9)-(11)

示例 4
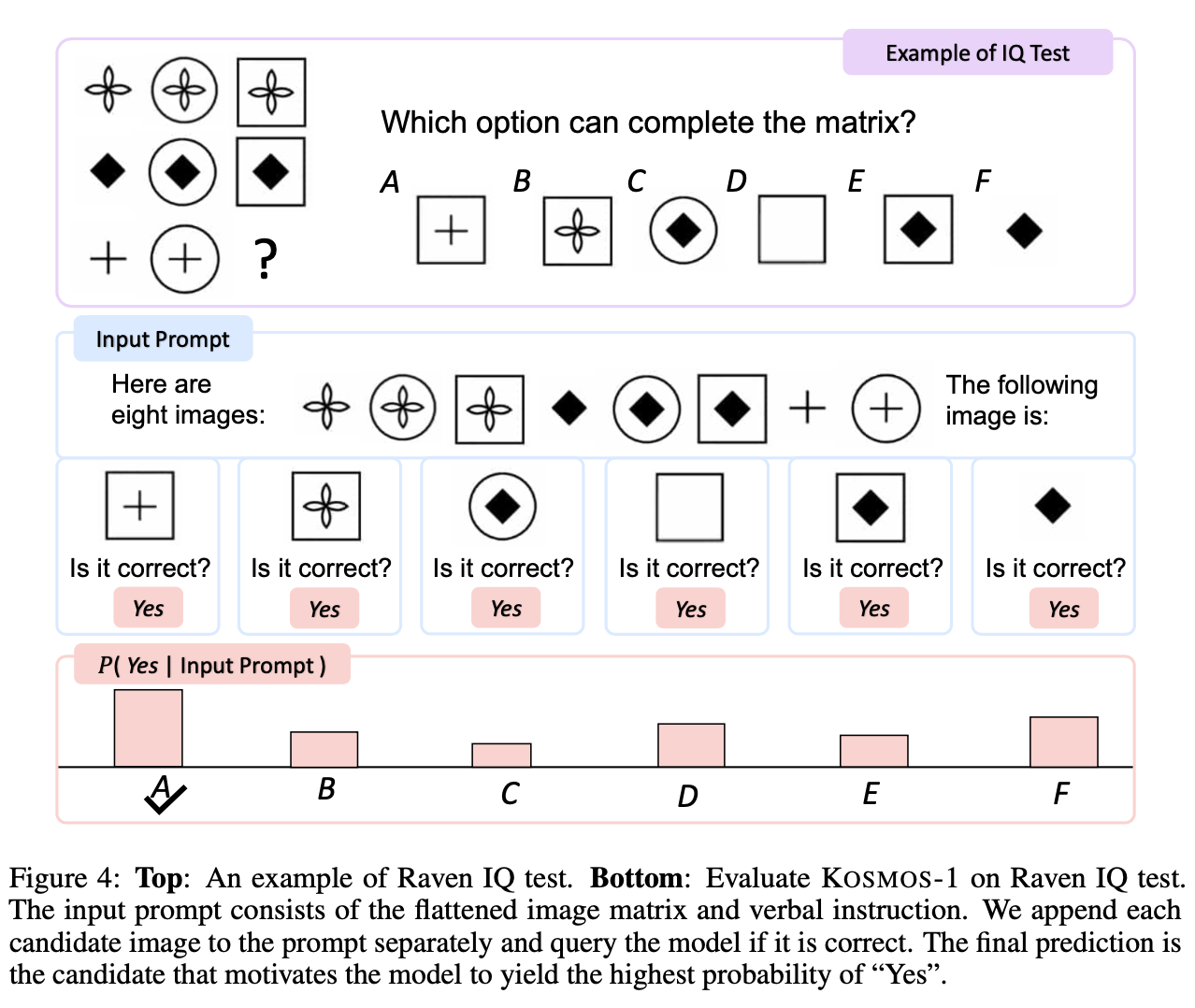
- 在Raven IQ测试中评估 KOSMOS-1
- Prompt 由平面图像矩阵和口头指令组成
- 我们将每个候选图像分别附加到提示上,并询问模型是否正确。最终的预测是促使模型产生最高概率的 "是 "的候选答案,使得 KOSMOS-1 具备非语言领域的推理能力
示例 5
- 多模态思维链:使KOSMOS-1首先产生一个理由,然后处理复杂的答题和推理任务

Kosmos-1总结&GPT-4
可以看出,多模态模型让 Kosmos-1 具备了可以理解图片的能力,识别图片内容,学习与图片相关的知识,甚至完成 IQ 测试,越来越向「人」的能力接近。
微软在月初表示其计划向开发人员提供 Kosmos-1,但该论文引用的GitHub页面还没有出现包括 Kosmos 的特定代码,会在 GPT-4 发布后一并更新吗?
GPT-4 除了能理解图像,还有声音和视频。也就是说,万事万物都可以被其理解和输出,我们又向 AGI(通用人工智能)迈进了一步,在有生之年可能会进入人和 AI 共存的世界,AI 可以直接通过摄像头和扬声器和人类沟通,越来越像「人」甚至超越「人」。
未来是像流浪地球2这样充满摄像头的世界,还是充满人造人的西部世界?

这样的世界很难想象,我们只能不断提升自己的能力来面对,驾驭 AI 而不是被 AI 淘汰

欢迎来推特一键三连。我会定期分享案例与思考,AI和NFT这类科技如何为企业、创作者和消费者带来改变
